

In this article, we’ll show you how to make your own tool that can recognize things in pictures. It’s called an object detection model, and we’ll use TensorFlow to teach it. We’ll explain each step clearly, from gathering pictures, preparing data to telling the model what to look for in them. By the end, you’ll have a powerful tool to spot objects in your own projects. Just make sure you have Python version 3.9 installed before we start!
Creating A Dataset
To build a dataset, begin by gathering images for training. In my case, I aim to train a model to detect plastic bottles, so I’ve collected images containing plastic bottles and stored them in a directory named “images.” Adding annotations to these images is essential for training the model. To create annotations, start by installing labelImg using:
“pip install labelImg”
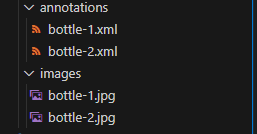
Then, run “labelImg” from the command prompt. With labelImg, you can mark objects in the images and save the file. Each image will have its corresponding XML file, saved in the “annotations” directory. The dataset format used here follows the pascal_voc standard.
Here’s a step-by-step demo of using labelImg:
- Click on “Open Dir” on the left side menu to select a directory containing images you want to label.
- Once an image is selected, click on the “Create RectBox” button to draw a box around the object of interest, such as a plastic bottle. Label it accordingly.
- If there are multiple objects in an image, repeat the previous step for each object.
- After labeling, click “Save” on the left side menu to generate an XML file.
- Click “Next” to move to the next image and repeat the labeling process from step 2.

This is how your images and annotations directory should look like
Prerequisites
Install the required packages
- pip install tflite-model-maker
- pip install numpy==1.23.5
- pip install tensorflow-datasets==4.8.3
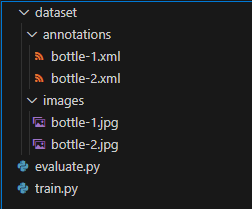
Directory Structure
As we will be carrying out a custom object detection project, having a simple yet effective directory structure is pretty much important.
Object Detection Model Training Process
from tflite_model_maker import object_detector
from tflite_model_maker import model_spec
import os
image_dir = os.path.join("dataset","images")
annotations_dir = os.path.join("dataset", "annotations")
data = object_detector.DataLoader.from_pascal_voc(image_dir, annotations_dir, label_map={1: "bottle"})
spec = model_spec.get('efficientdet_lite4')
spec.config.var_freeze_expr = 'efficientnet'
model = object_detector.create(data,model_spec=spec, epochs=100, batch_size=2,train_whole_model=True)
# Export the trained model.
model.export(export_dir='.')This code snippet demonstrates the process of training a machine learning model to detect objects in images, with a focus on identifying bottles. Here’s a breakdown of the steps:
1. Importing Libraries:
- tflite_model_maker: This library helps in creating TensorFlow Lite models easily.
- model_spec: This library provides predefined model specifications.
Defining Directories:
- image_dir: This variable stores the directory path where images for training are stored.
- annotations_dir: This variable stores the directory path where annotations (labels) for the images are stored.
Loading Data:
- Object_detector.DataLoader.from_pascal_voc: This function loads the data from the Pascal VOC format, which is a standard format for storing annotations (bounding boxes around objects) along with images. It loads images from image_dir and their corresponding annotations from annotations_dir. In this case, it’s looking for bottles, which are labeled as class 1.
Defining Model Specification:
- model_spec.get(‘efficientdet_lite4’): This line defines the model specification. It selects a specific pre-trained model called “efficientdet_lite4”, which is an efficient object detection model.
Creating the Model:
- object_detector.create: This function creates the object detection model using the provided data and model specification. It trains the model for 100 epochs (iterations over the entire dataset), with a batch size of 2, and trains the entire model (not just the top layers).
Exporting the Trained Model:
- model.export(export_dir=’.’): This line exports the trained model to the current directory. The model can then be used for inference (making predictions) on new images.
Making Predictions With The Trained Object Detection Model
Now that the model has been trained, it’s ready to make predictions by loading the saved model.
import cv2
import numpy as np
from PIL import Image
import tensorflow as tf
from tflite_support import metadata
from tflite_model_maker import object_detector
model_path = 'model.tflite'
# Load the TFLite model
interpreter = tf.lite.Interpreter(model_path=model_path)
interpreter.allocate_tensors()
displayer = metadata.MetadataDisplayer.with_model_file(model_path)
# Load label list from metadata.
file_name = displayer.get_packed_associated_file_list()[0]
label_map_file = displayer.get_associated_file_buffer(file_name).decode()
label_list = list(filter(lambda x: len(x) > 0, label_map_file.splitlines()))
# Load labels (if available)
num_classes = len(label_list)
classes = ['???'] * num_classes
for label_id, label_name in enumerate(label_list):
classes[label_id] = label_name
# Define a list of colors for visualization
COLORS = np.random.randint(0, 255, size=(len(classes), 3), dtype=np.uint8)1. Loading the Model:
- interpreter = tf.lite.Interpreter(model_path=model_path): This line loads the TensorFlow Lite model from the specified path.
2. Loading Metadata:
- displayer = metadata.MetadataDisplayer.with_model_file(model_path): This line loads metadata associated with the model.
- label_map_file = displayer.get_associated_file_buffer(file_name).decode(): It extracts label information from the metadata.
def preprocess_image(image_path, input_size):
"""Preprocess the input image to feed to the TFLite model"""
img = tf.io.read_file(image_path)
img = tf.io.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.uint8)
original_image = img
resized_img = tf.image.resize(img, input_size)
resized_img = resized_img[tf.newaxis, :]
resized_img = tf.cast(resized_img, dtype=tf.uint8)
return resized_img, original_image3. Preprocessing the Image:
- preprocess_image function: This function reads an image from a file, resizes it to the required input size for the model, and prepares it for feeding into the model.
def detect_objects(interpreter, image, threshold):
"""Returns a list of detection results, each a dictionary of object info."""
signature_fn = interpreter.get_signature_runner()
# Feed the input image to the model
output = signature_fn(images=image)
# Get all outputs from the model
count = int(np.squeeze(output['output_0']))
scores = np.squeeze(output['output_1'])
classes = np.squeeze(output['output_2'])
boxes = np.squeeze(output['output_3'])
results = []
for i in range(count):
if scores[i] >= threshold:
result = {
'bounding_box': boxes[i],
'class_id': classes[i],
'score': scores[i]
}
results.append(result)
return results4. Detecting Objects:
- detect_objects function: This function runs object detection on the preprocessed image using the loaded model interpreter. It returns a list of detected objects along with their bounding boxes and confidence scores.
def run_odt_and_draw_results(image_path, interpreter, threshold=0.5):
"""Run object detection on the input image and draw the detection results"""
# Load the input shape required by the model
_, input_height, input_width, _ = interpreter.get_input_details()[0]['shape']
# Load the input image and preprocess it
preprocessed_image, original_image = preprocess_image(
image_path,
(input_height, input_width)
)
# Run object detection on the input image
results = detect_objects(interpreter, preprocessed_image, threshold=threshold)
# Plot the detection results on the input image
original_image_np = original_image.numpy().astype(np.uint8)
for obj in results:
# Convert the object bounding box from relative coordinates to absolute
ymin, xmin, ymax, xmax = obj['bounding_box']
xmin = int(xmin * original_image_np.shape[1])
xmax = int(xmax * original_image_np.shape[1])
ymin = int(ymin * original_image_np.shape[0])
ymax = int(ymax * original_image_np.shape[0])
# Find the class index of the current object
class_id = int(obj['class_id'])
# Draw the bounding box and label on the image
color = [int(c) for c in COLORS[class_id]]
cv2.rectangle(original_image_np, (xmin, ymin), (xmax, ymax), color, 2)
# Make adjustments to make the label visible for all objects
y = ymin - 15 if ymin - 15 > 15 else ymin + 15
label = "{}: {:.0f}%".format(classes[class_id], obj['score'] * 100)
cv2.putText(original_image_np, label, (xmin, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# Return the final image
original_uint8 = original_image_np.astype(np.uint8)
return original_uint85. Drawing Results on Image:
- run_odt_and_draw_results function: This function takes an image path, runs object detection on it, and draws bounding boxes and labels on the image based on the detected objects.
INPUT_IMAGE_URL = "test_images/bottle.jpg"
DETECTION_THRESHOLD = 0.3
# Run inference and draw detection result on the local copy of the original file
detection_result_image = run_odt_and_draw_results(
INPUT_IMAGE_URL,
interpreter,
threshold=DETECTION_THRESHOLD
)
detection_result_image_rgb = cv2.cvtColor(detection_result_image, cv2.COLOR_BGR2RGB)
cv2.imwrite("image.png", detection_result_image_rgb, [cv2.IMWRITE_PNG_COMPRESSION, 0])6. Running Object Detection and Displaying Results:
- run_odt_and_draw_results is called with the input image URL and other parameters like the detection threshold.
- Detected objects are drawn on the image, and the result is saved as an image file and displayed.
- The final detection result image is converted to RGB format and displayed.
Result











